Leveraging Compressed Video Latents for Efficient Video Classification
Introduction
Recent advances in video compression and generation models have unlocked new ways to efficiently represent video data. The Reducio-VAE, introduced in this paper, is a Variational Autoencoder (VAE) designed to compress video content into extremely compact latent representations. Originally developed to enable fast video generation using diffusion models, this VAE achieves a 64× reduction in latent space while maintaining high reconstruction quality.
In our research, we explored an alternative use case for these compressed representations: video classification. Instead of training a full end-to-end video classification model, which can be computationally expensive, we leveraged the latent encodings produced by Reducio-VAE as input features for a classifier. This approach significantly reduces computational costs while still achieving strong classification performance.
In this blog post, we will walk through our methodology, the benefits of using compressed latents for classification, and the results of our experiments.
Problem Statement
The internet these days is built on videos and images with 82% of the yearly traffic being video streams. Specifically, the rapid growth of video data has increased the need for an efficient (and scalable) video compression model that can reduce training dataset sizes and speed up the process of training and inference in video classification models.
This project investigates whether the highly compressed latent representations generated by the Reducio-VAE (originally designed for fast video generation) can capture intrisic semantic information about the video content. In particular, we examine if these latent encodings can effectively serve as a low-dimensional but rich feature set for training an action classification model. The key questions which we aim to address are:
- Can Reducio-VAE’s compressed latents preserve the essential semantic info needed to distinguish between different actions?
- How does the performance of action classifiers trained on these latents compare to end-to-end models using full resolution outputs?
- What are the trade-offs in terms of computational efficiency vs classification accuracy when using such compressed representations?
Dataset & Preprocessing
Reducio-VAE
Reducio-VAE is a variational autoencoder designed for video input. It uses 3D convolutional layers to compress video clips into a compact latent space while preserving essential motion. The model consists of two main components: an encoder and a decoder. The encoder reduces the input video to a latent tensor, achieving up to a 64× reduction in dimensionality. The decoder reconstructs the video from this latent code, guided by a reference content frame to retain fine details.
 Figure 1: Reducio-VAE architecture
Figure 1: Reducio-VAE architecture
The latent representation captures both motion dynamics and semantic information. When decoded, it produces a video sequence with high visual fidelity, even under heavy compression. Below are frames from a reconstruction of a 112-frame, 320×240 video.
 Figure 2: Original vs reconstructed frames
Figure 2: Original vs reconstructed frames
During our experimentation with the Reducio-VAE, we also encountered several issues that required careful troubleshooting and modifications:
- Setting up the environment was more challenging than expected. Key dependencies such as taming-transformers and xformers failed to load correctly with the latest Python versions. These incompatibilities were not documented in the repository, forcing us to downgrade our Python version to 3.9 for successful installation and execution.
- The inference pipeline also presented its own challenges. Specifically, the code was unable to correctly load complete video files. Instead, it incorrectly chunks the videos by relying on a file used as meta information, which contains the video filename and its location within the video data root. This misinterpretation required us to modify the inference routine to ensure proper loading and reconstruction of the video sequences.
Dataset
For our experiments we selected the UCF101 dataset which consists of 13,320 video clips, across 101 classes. Each clip has a fixed resolution of 320×240 pixels and a duration ranging from approximately 5 to 20 seconds at 25 frames per second. This is important because requires videos to have at least 256 pixels in each dimension (for their 256x256 pixel VAE model).
Preprocessing
To prepare the dataset for use with Reducio-VAE, we applied the following preprocessing steps:
- Frame extraction: Reducio-VAE was trained on 1 second long 16 fps video clips. To match the input we extracted the frames from the videos and grouped them in batches of 16. Remaining frames were removed.
- Resizing and padding: Frames were resized and padded to ensure they met the dimensional requirements of Reducio’s convolutional architecture.
- Encoding with Reducio-VAE: The processed frame sequences were passed through the Reducio encoder to generate highly compressed latent representations, reducing the original input dimensionality from (16,1,320,240) to (16,4,7,9).
Experiments
For our experiments, we trained three different classifiers to explore the volatility of our approach and assess whether various models can effectively use the information captured from Reducio’s compressed outputs to reliably classify data. The architectures we chose were a simple LSTM, a transformer model, and a 3D convolutional network. Rather than focusing on optimizing any single model, our goal was to explore the overall feasibility of the project.
LSTM
Our recurrent model processes a sequence of 16 video frames by first encoding each frame using the Reducio-VAE, which compresses the visual information into a latent representation of shape 4 × 7 × 9 per frame. These compressed outputs are then passed through an adaptive pooling layer, reducing each to a uniform shape of 2 × 2 × 2, resulting in a sequence of 16 feature vectors. This sequence is fed into a two-layer LSTM, which captures temporal dependencies across the frames. The LSTM’s final hidden state, shaped as 16 × 128, is passed through a linear layer to produce the final action prediction.
The reason we use a sequence of 16 frames in each batch is that Reducio-VAE encodes temporal relationships between frames, embedding information within the latent representations. By keeping the frames grouped together, we ensure that these temporal embeddings are preserved throughout the processing pipeline. This method helps maintain continuity across the sequence, enabling the model to better capture the nuanced temporal dependencies and improve action classification performance.
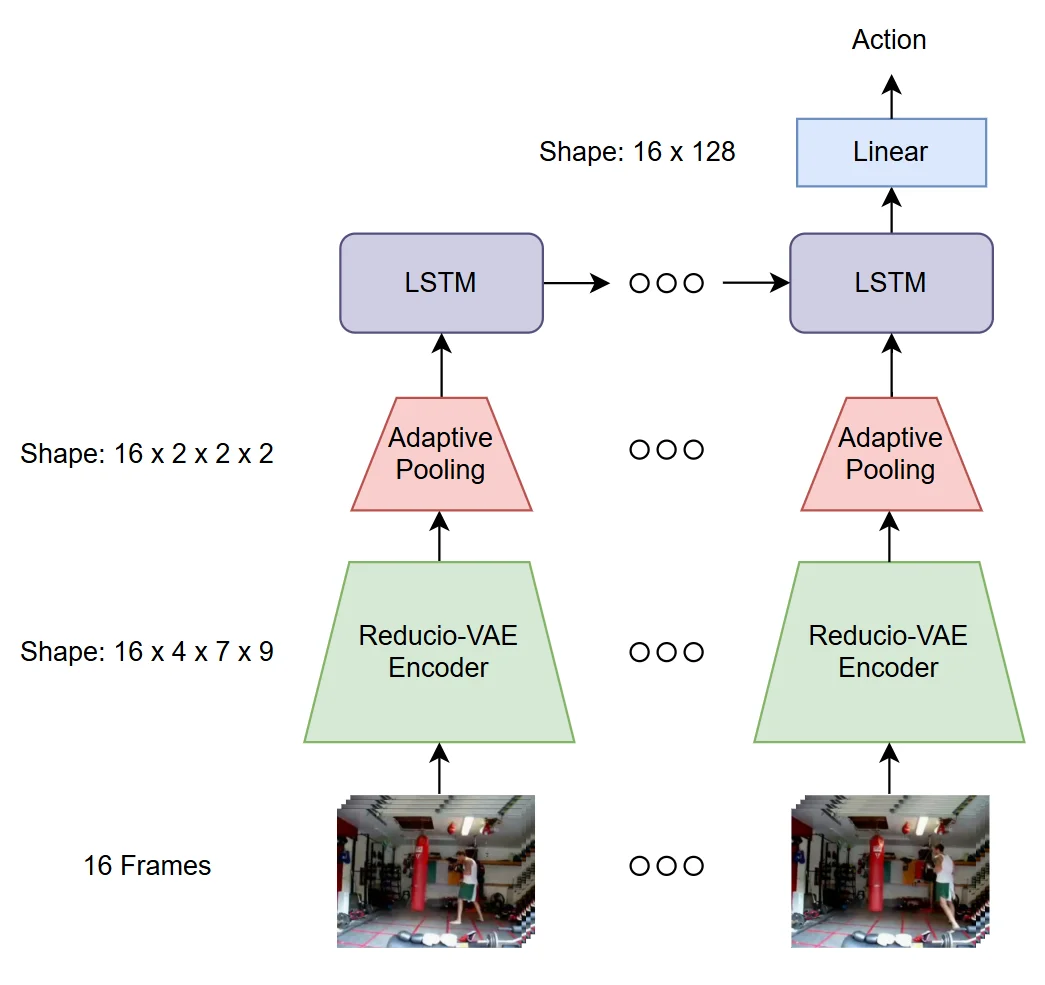 Figure 3: LSTM model architecture
Figure 3: LSTM model architecture
This architecture achieved a 96.07% accuracy on the train set, 52.72% on the validation set and 54.30% accuracy on the test set. The training took ~36 minutes using an RTX 3070 consumer-grade laptop GPU with CUDA 12.4 and PyTorch 2.6.0.
 Figure 4: LSTM performance graph
Figure 4: LSTM performance graph
Transformers
Our transformer-based classifier leverages the self-attention mechanism to model long-range temporal dependencies across compressed video frames. Like the other architectures in our study, each frame is first encoded by Reducio-VAE into a latent representation of shape 4×7×9. These latent representations are then flattened (each resulting in a 4032-dimensional vector) and projected into a higher-dimensional hidden space. Additionally, learnable positional embeddings are added to retain the sequential ordering of frames, which is crucial for capturing temporal relationships + a learnable class token (used in the final classification head).
 Figure 5: Transformers model architecture
Figure 5: Transformers model architecture
The transformer architecture is implemented via a series of encoder layers, each employing multi-head self-attention and feedforward networks. This design allows the model to focus on different parts of the sequence concurrently, effectively extracting global features that span the entire input sequence. After processing through the transformer blocks, the sequence is cut and only the class token is kept, which compacts the temporal information into a single feature vector. This token is then passed through a dropout layer to mitigate overfitting before the final linear layer produces the class logits.
 Figure 6: Transformers performance graph
Figure 6: Transformers performance graph
By looking at the results such as the training and validation loss curves, we can see that the model heavily overfits. Similar behaviour is exhibited no matter the size of the hidden dimension, the learning or dropout rate. As such it is fair to assume that, the transformer architecture doesn’t quite work mainly due to the amount of data available (as Transformers notoriously need a lot of data to generalize).
This architecture achieved 97% accuracy for training, 32% for validation and 30% for testing. The training took ~15 minutes using an RTX 4080 consumer-grade laptop GPU with CUDA 12.4 and PyTorch 2.6.0.
3D-Convolutional Network
The convolutional network’s input is the same as that of the LSTM, a tensor of shape (16x4x7x9), with 101 raw logits as its output. It’s trained using cross-entropy loss, from PyTorch’s criterion, which applies a softmax function and the negative log-likelihood calculations, to the aformentioned logits, to backpropagate. Varying classifications for multiple 1-second clips can be collated or averaged to determine actions for entire variable-length video files.
The network’s architecture can be explained in two blocks: the 3D-conv block (purple), and the classifier block (blue). The goal of the 3D-conv block is to reduce the number of dimensions and capture spatio-temporal constraints while the classifier block is an MLP with residual connections which learns what action is encoded in the 128 channels.
Both convolutions and max pooling layers, specific to Reducio’s UCF-101 latents, guarantee that we reduce all dimensions to 1 while introducing an appropriate amount of channels to extract signals from. The rest of the 3D-conv block follows common convolutional network conventions, such as batch normalization and ReLU activation.
Finally, action prediction is done by the classifier block, which reads all 128 channels and determines what patterns in the channels correspond to the respective action we’re classifying. Residual connections are present as they further stabilize training and gradient calculations.
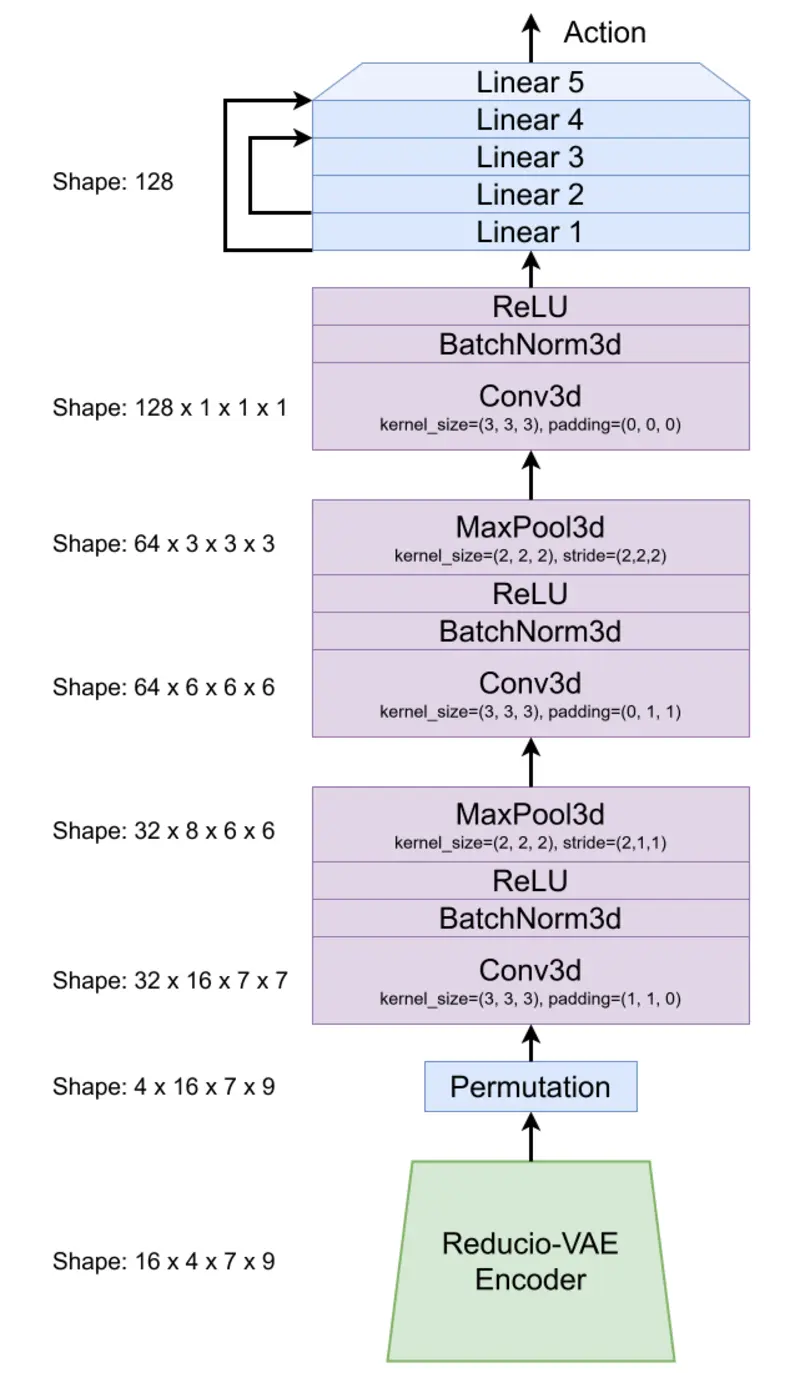 Figure 7: 3D-Conv model architecture
Figure 7: 3D-Conv model architecture
Ultimately, the 3D-Convolutional Network achieved a training accuracy of 92.33%, validation accuracy of 70.47%, and test accuracy of 72.47%. The slight increase in test accuracy over validation could be due to the test set including less video clips overall. The training took ~16 minutes using an RTX 4070 consumer-grade GPU with CUDA 12.4 and PyTorch 2.6.0.
 Figure 8: 3D-Conv performance graph
Figure 8: 3D-Conv performance graph
A majority of the architectural decisions were impacted by observing the previous models’ problems and empirical evaluation of the training/validation metrics. For example, to handle the overfitting problem experienced by both the LSTM and Transformer, the linear layers at the end are heavily regularized with a dropout of 0.5 so they don’t learn a direct correlation between one value from the 128 channels and one label from the 101 classes. Other decisions such as the addition of residual connections, greatly decreased the amount of time it took for the network to converge, from 120 epochs to 17, which was cut-and-try experimentation. We also experimented with increasing the dimensionality in the MLP, similar to a VAE, but that approximated the simpler MLP and took longer to converge.
In terms of relative performance, the 3D-Convolutional Network seems to outperform the previous models due to its stable training, as shown by the learning curves, and custom-made dimensionality reduction which captures spatio-temporal constraints easily.
Conclusion & Future Work
In this research, we explored a novel application of Microsoft’s Reducio VAE and its potential to transform the approach to video classification. Traditionally, video classification models rely on processing the entire video in an end-to-end manner, requiring substantial computational resources and time. However, our findings indicate that such an approach may not be necessary. Through a series of controlled experiments, we demonstrated that the amount of information required for a model to accurately classify an action within a video is far less than the complete video itself. This discovery not only challenges traditional paradigms but also opens up new avenues for more efficient video classification techniques.
By utilizing the Reducio VAE, we showed that it is possible to extract relevant features from videos in a way that drastically reduces the amount of data needed for effective classification. This reduction in data complexity could lead to more lightweight models, capable of processing video content without sacrificing performance. Furthermore, our results highlighted a significant reduction in inference time, meaning that the time it takes to classify new video data is considerably faster compared to traditional methods. This improvement in speed, coupled with the reduced data requirements, suggests that video classification can become more efficient, scalable, and adaptable to a wider range of real-world applications.
This research has opened up numerous opportunities for future work. While our models show promising performance, considering the number of classification classes and their accuracy, they do not yet achieve state-of-the-art results on the dataset we tested. It is important to emphasize, however, that achieving state-of-the-art performance was not the primary objective of this project. Our goal was to demonstrate the feasibility of this approach across different model architectures. Therefore, our findings provide a foundation for further exploration into how close this method can come to reaching state-of-the-art performance.
Moreover, our solution currently relies on a single modality, as Reducio does not support sound and only processes RGB video data. There are, however, other potential ways to capture additional modalities that could enhance classification in a more compressed format. For example, exploring the feasibility of incorporating depth information and evaluating its impact on classification accuracy could be an interesting direction for future research. This could provide valuable insights into how multimodal data might improve model performance while maintaining efficiency.
References
[1] - Tian, R., Dai, Q., Bao, J., Qiu, K., Yang, Y., Luo, C., Wu, Z., & Jiang, Y.-G. (2024). REDUCIO! Generating 1024×1024 Video within 16 Seconds using Extremely Compressed Motion Latents. arXiv:2411.13552. https://arxiv.org/abs/2411.13552
Team Contributions
Alex Lalov - 3D-Conv model implementation
Alexandros Dimakos - LSTM model implementation
Angelos Mangos - Transformers model implementation
Thanks for reading!